- Published on
Detecting Offensive Meaning in Multilingual Marketing Content with Amazon Bedrock
- Authors

- Name
- Benjamin Lee
The marketing campaigns that end in a public apology are rarely the ones that contain an obvious slur. Those get caught. The costly failures are the assets where every word is individually clean, every image is individually safe, and the problem appears only when they combine: a tagline that reads as innocuous in isolation but lands as an explicit pun, a product name that becomes a crude homophone, or a caption that inverts the meaning of the photo above it. The risk grows across a language boundary, because the reviewer approving a Korean campaign may be reasoning in English.
This is a detection problem rather than a generation problem, and it maps well onto a batch pipeline. Marketing assets arrive in waves ahead of a launch, they must clear review before they ship, and the objective is to narrow the field so that human reviewers spend their attention on the few assets that genuinely carry risk. In this post, we present a batch architecture on AWS that detects illegal, sexual, and offensive meaning across text, image, video, and audio in English and Korean. We also explain why a multimodal foundation model now belongs at the center of the design, and when a lighter approach is the better choice.
The challenge with managed classifiers alone
The established AWS approach to content moderation composes one managed service per signal: Amazon Rekognition for images and video, Amazon Transcribe for audio, Amazon Comprehend for text, and Amazon Translate to normalize language (content moderation design patterns). These services remain excellent at detecting explicit content, and they are inexpensive at high volume, which keeps them valuable as a first-pass filter.
Their limits become apparent on a Korean campaign. Amazon Comprehend supports Korean for sentiment, entities, and key phrases, but its PII detection is limited to English and Spanish, and its toxic-content detection runs on English only (Comprehend languages, Comprehend trust and safety). Amazon Transcribe Toxicity Detection classifies spoken audio using speech cues such as tone and pitch, but it too is English only (Transcribe toxicity). Amazon Rekognition can read text inside an image, yet its text detection covers English and several mostly European scripts, not Korean (content moderation design patterns).
The result is strong, language-agnostic coverage of imagery and very little coverage of the nuanced linguistic risk that actually sinks campaigns. More fundamentally, these classifiers label what is present; they do not reason about what a clean phrase implies when it is read a second way. Closing that gap calls for a different core.
Solution overview
Three Amazon Bedrock capabilities released since the original pattern change the recommended design.
First, Amazon Bedrock Data Automation became generally available in 2025 as a single managed service that extracts structured insight from documents, images, audio, and video (Bedrock Data Automation general availability). It replaces the work of orchestrating several extraction services by hand, and it now supports synchronous image processing for moderation use cases (synchronous image processing).
Second, multimodal foundation models available in Amazon Bedrock, such as Anthropic Claude and Amazon Nova, can read the Korean text rendered inside an image and reason about its meaning in a single request. This removes the Rekognition OCR language gap, and AWS publishes media-compliance reference guidance built on Amazon Nova (content compliance with Amazon Nova). It is the capability the earlier classifiers lacked: a model that interprets a pun rather than only matching a banned word.
Third, Amazon Bedrock Guardrails added multimodal support. Image content filters are generally available and, according to AWS, help block up to 88% of harmful multimodal content (Guardrails image content filters). Filtering spans six categories across text and images with configurable strength (content filters). The ApplyGuardrail API applies a guardrail to any content as a standalone check, independent of a model invocation (ApplyGuardrail API), which makes it a deterministic policy engine you can point directly at an asset.
Together these reduce the detection core from several stitched-together services to three components: Amazon Bedrock Data Automation for extraction, a multimodal model for understanding, and Amazon Bedrock Guardrails for deterministic policy. The contextual reasoning and the optical character recognition now happen in one place, natively in the source language.
Architecture walkthrough
The following diagram illustrates the end-to-end flow.
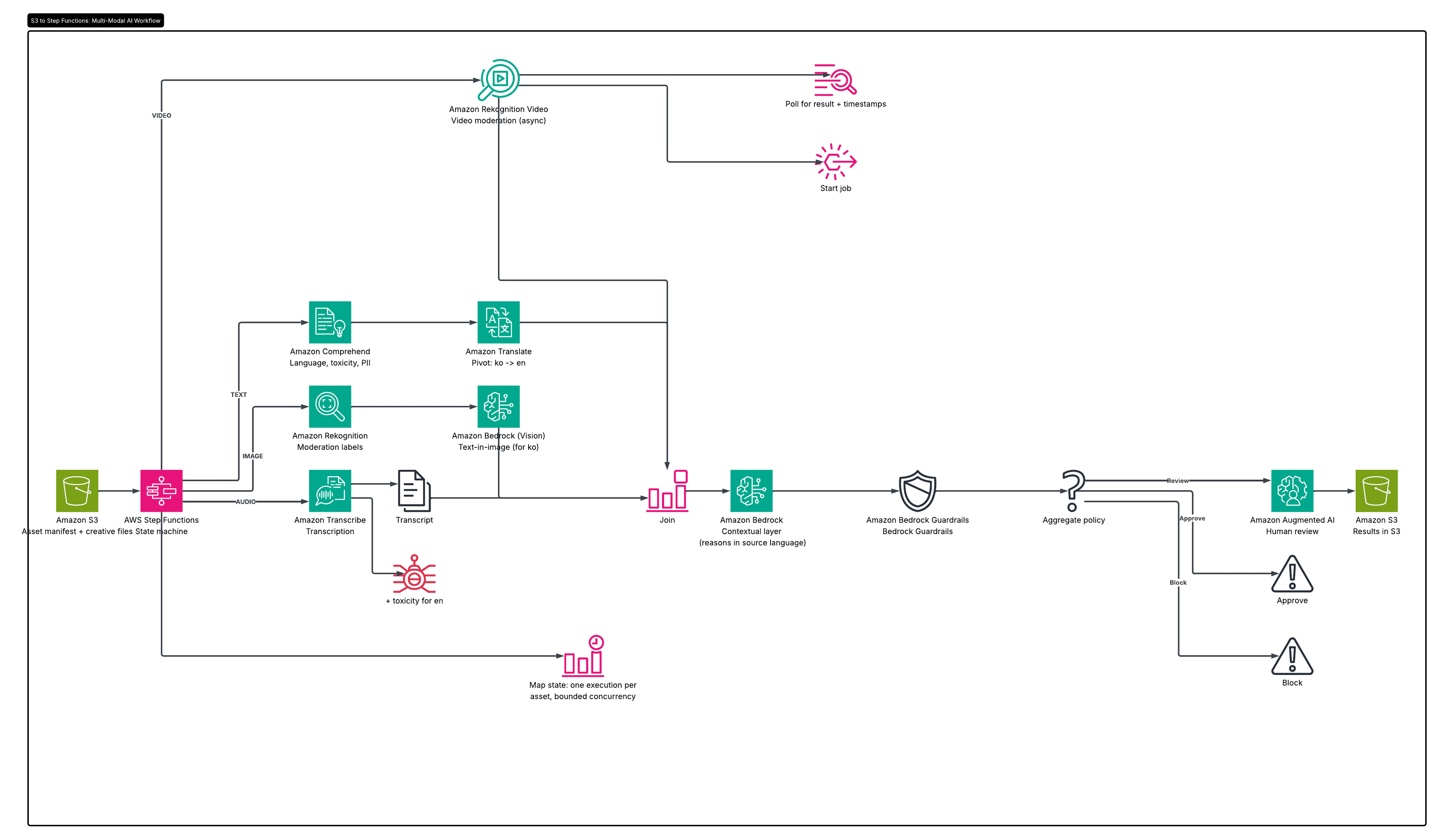
S3 (asset manifest + creative files)
|
v
Step Functions [Map state: one execution per asset, bounded concurrency]
|
+--> Bedrock Data Automation : one call extracts text, transcript,
| frames, and structured insight from image, video, audio, document
|
+--> Multimodal FM (Claude / Amazon Nova) : reads Korean-in-image and
| reasons about hidden, compositional meaning in the source language
|
+--> Bedrock Guardrails (ApplyGuardrail) : deterministic multimodal
| policy across text and image, tunable strength per category
|
+--> (optional) Rekognition / Comprehend : cheap high-volume prefilter
|
v
Aggregate policy -> approve | review | block
|
v
Amazon A2I human review -> results in S3
The pipeline works as follows:
- A manifest of assets and the creative files land in an Amazon S3 bucket.
- AWS Step Functions reads the manifest and uses a Map state to process assets in parallel, with bounded concurrency, so that each asset is handled by one invocation.
- Amazon Bedrock Data Automation extracts the content of each asset into a normalized form: copy, transcripts, text rendered on frames, and structured insight. Video and audio jobs run asynchronously, so the workflow starts the job, waits, and collects the result.
- A multimodal foundation model in Amazon Bedrock evaluates the extracted text and, for images, the image itself. It reads any Korean text in the image and reasons about hidden or compositional meaning in the original language.
- Amazon Bedrock Guardrails, invoked through the ApplyGuardrail API, applies the deterministic policy across text and image.
- A policy layer aggregates the findings into a single decision: approve, send for review, or block.
- Assets that require review route to Amazon Augmented AI (Amazon A2I), and the results are written back to Amazon S3.
We call this shape compositional decomposition: break each asset into the parts a model can reason over, such as the words, the transcript, the text on a frame, and the scene, and then evaluate those parts both individually and in combination. The combination step is where the offensive reading lives, and it is precisely what a single classifier per modality cannot detect.
Processing assets in batch
AWS Step Functions orchestrates the batch. The Map state fans out across the manifest with bounded concurrency, and each asset becomes one AWS Lambda invocation that calls Amazon Bedrock Data Automation, the multimodal model, and the guardrail (AWS Step Functions). Because video and audio extraction is asynchronous, the workflow starts the job and polls for completion rather than holding a function open.
Each asset produces a set of findings, and a deterministic policy layer reduces them to one decision. A worst-case severity at or above the block threshold prevents publication, a severity at or above the review threshold queues the asset for a human, and anything below is approved. Separating policy from detection is intentional: the routing rules remain auditable and can be tuned against a labelled validation set without changing the model prompts. As a safeguard, any detector error forces human review rather than silent approval, so a failed call never reads as a pass.
Assets that require review route to Amazon A2I, which manages the human review workflow and integrates directly with Amazon Rekognition when you keep a visual prefilter (Amazon A2I human review). This is where the operational economics hold up. AWS notes that, with machine learning pre-filtering, human moderators typically review on the order of 1-5% of total volume rather than every asset (Rekognition moderation). The pipeline narrows the queue, and people make the final call on what remains.
Benefits and when to use this architecture
The orchestration backbone is unchanged from the established pattern, and that is deliberate: a serverless design, batch fan-out through AWS Step Functions, and human-in-the-loop review remain the right foundation. The gains come from the foundation model core, and they are concrete.
- Native understanding in the source language. A single multimodal model reads the Korean text rendered inside an image and reasons about its meaning in one request, which removes both the Rekognition OCR gap and the translate-then-classify detour. The offensive reading is evaluated in Korean rather than in a lossy English translation.
- Compositional meaning rather than labels. The model weighs the words, the image, and the way a caption combines with a picture together, which is the failure mode a per-modality classifier cannot see.
- Fewer moving parts. Amazon Bedrock Data Automation consolidates per-service extraction into one ingestion call (Bedrock Data Automation general availability), which means less custom code to operate and maintain.
- A deterministic policy boundary you configure rather than code. ApplyGuardrail applies a guardrail to any text or image independent of the model and is tuned by category strength (ApplyGuardrail API). Guardrails now filter images as well as text, which AWS reports blocks up to 88% of harmful multimodal content (Guardrails image content filters).
- Reviewer effort focused where it matters. Pre-filtering keeps reviewers on a small share of assets, and the model's written explanation of each finding speeds the decision.
This architecture fits best when you review marketing and brand creative ahead of launch, across languages and modalities, when volume is bounded and arrives in waves, and when a single missed double meaning is expensive. It is equally well suited to situations where nuance and cultural context matter more than raw throughput, such as multilingual campaigns, regulated categories, and content destined for high-visibility public placement. The richer and more ambiguous the content, the more the model core justifies its cost.
A lighter approach can be the better choice for open, real-time, very high-volume content such as user-generated uploads or live chat. There, foundation model inference is probabilistic and costs more per item than a managed classifier, so a Rekognition or Comprehend prefilter ahead of the model, or a streaming moderation pattern in place of batch, carries most of the load at lower cost. That is why the prefilter remains in the diagram as an optional first pass. If your content is English only and the risk is limited to explicit material rather than hidden meaning, the managed classifiers on their own may be sufficient.
Best practices
A few decisions are easy to get wrong, and worth calling out.
Reason in the original language. The most common mistake is to translate everything into English first and run a single detector, which discards the signal you most need, because the offensive reading often exists only in the source language. A multimodal model removes the need to translate first, since it can reason in Korean directly.
Make human review the default for anything ambiguous. A false positive costs a few minutes of a reviewer's time. A false negative can cost a campaign. Set thresholds with that asymmetry in mind.
Treat the model as advisory and the guardrail as the deterministic boundary. The model is effective at surfacing candidates and explaining why a phrase may read badly, but it should not block on its own confidence. Pair it with a guardrail for the firm policy lines and with people for judgment.
Cache by content hash. Re-scanning unchanged assets across iterations is wasteful, and the foundation model calls dominate per-asset cost on text-heavy batches.
Validate language coverage before you commit. Amazon Bedrock Guardrails language support varies by policy and safeguard tier, so test Korean coverage rather than assuming it (Guardrails languages).
Conclusion
The managed classifiers are the inexpensive part of this system, and they still earn a place as a prefilter. The reason brand-safety failures persist is the clean-but-loaded phrase, the pun that works only in Korean, and the caption that recontextualizes the image. That signal cannot be bought as a label. With a multimodal foundation model that decomposes an asset and reasons about its combined meaning in the source language, fenced by a deterministic guardrail and backed by human review, it becomes a first-class step in the pipeline. The outcome is a short, explained list of assets a person should examine before the campaign goes live, rather than a wall of green checkmarks that hides the one that matters.
References
- Content moderation design patterns with AWS managed AI services
- Amazon Bedrock Data Automation is now generally available
- Amazon Bedrock Data Automation now supports synchronous image processing
- Streamlining content compliance: automating media analysis with Amazon Nova
- Amazon Bedrock Guardrails image content filters (general availability)
- Configure content filters for Amazon Bedrock Guardrails
- Amazon Bedrock ApplyGuardrail API
- Amazon Bedrock Guardrails: supported languages
- Amazon Comprehend: languages supported
- Amazon Comprehend: trust and safety
- Amazon Transcribe: detecting toxic speech
- Amazon Rekognition: moderating content
- Amazon Augmented AI: human review loops
- AWS Step Functions: what is AWS Step Functions